Cognita : A Truly Unified RAG Framework : Part 1
Why care, when there’s so many out there?


Why care, when there’s so many out there?
🤔 RAG (Retrieval Augmented Generation) systems are powerful, but building and deploying them can be tricky.
🚀 Cognita aims to be a user-friendly and modular solution that addresses common RAG challenges.
In Search of a True Production-Grade Complete RAG framework
Issues with current frameworks:
⚙️ Chunking & embedding jobs often need separate setup, but not built-in in current frameworks known to Author as of now.
💻 Deploying query services for production can be complex
🤖 Handling model deployment (language models, embedding models) lacks built-in support.
🗄 Vector databases can be tricky to deploy for scalability.
🧩 No single, ready-to-use template for easy adoption
⚠️ Disclaimer: These issues may have been addressed by other frameworks, not known to Author as of this writing.
How Cognita Solves These Issues
🎯 Cognita balances customization with ease of use.
🧠 Scalable design to integrate breakthroughs as they happen.
Cognita — A Library for building modular, open source RAG applications for production
🧱 Modular Design: Break down RAG into steps for easier management and updates.
♻️ Reusable components: Parsers, loaders, etc., to save time across projects.
🚀 Streamlined Deployment: Cognita handles the nitty-gritty of production systems.
⚖️ Scalability: Components scale independently to handle increased traffic.
✨ User-friendly Interface: Even non-technical users can play with RAG setups.
🔌 API-Driven: Cognita works well with other systems.
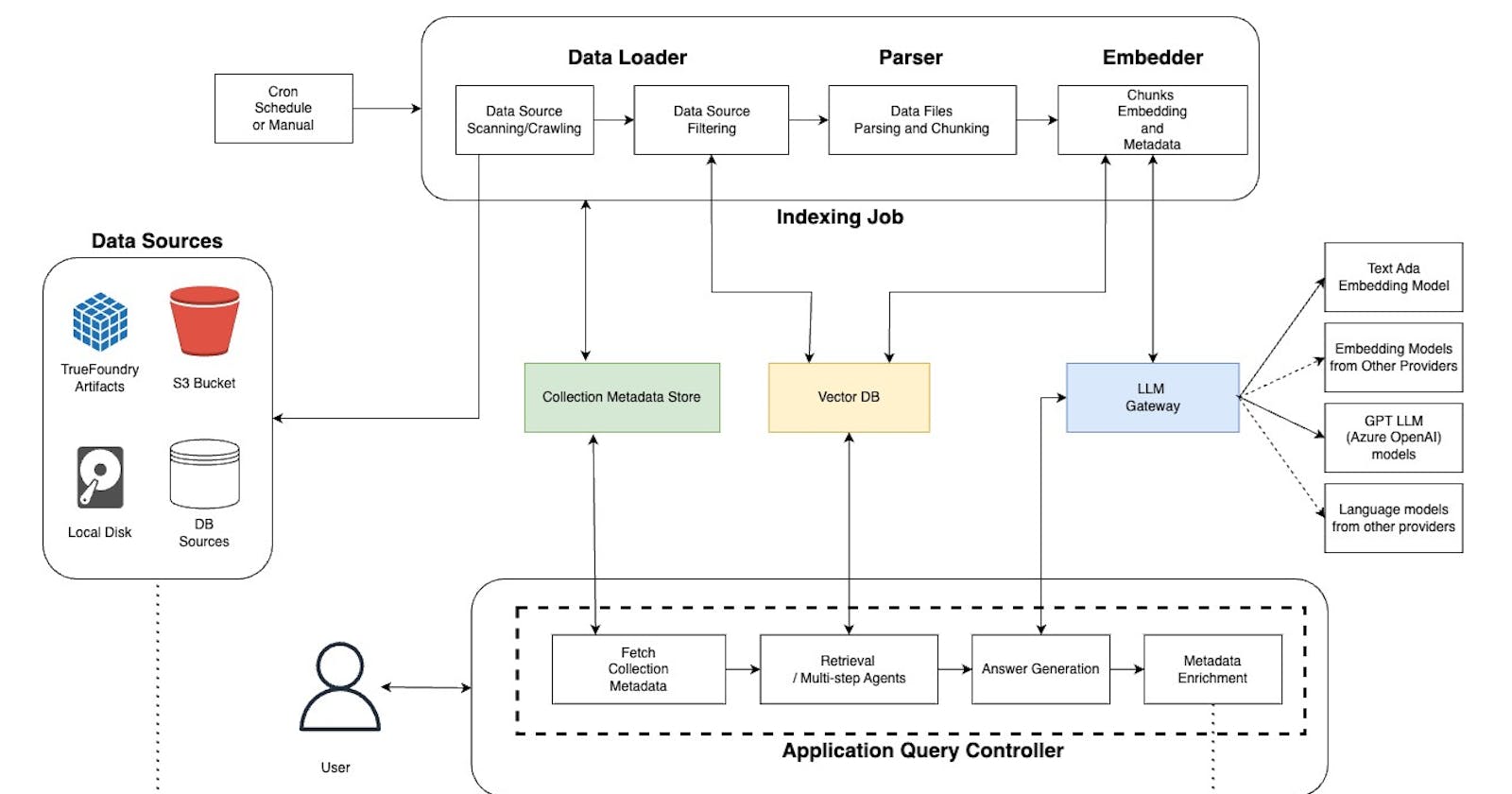
Cognita Components
Indexing Job
1. Data Loaders 🚚
What: Fetch data from various places (folders, databases, etc.).
Why: RAG needs data to work with!
2. Parsers 🗂️
What: Turn different file types into a common format.
Why: Makes it easier for the RAG system to process everything.
3. Embedders 🔎
What: Create code-like representations of text for fast comparison
Why: Helps find the most relevant info for your question.
Metadata Store 🧠
What: The 'brain' of the system, storing configuration details
Why: Keeps your RAG organized and easy to manage.
LLM Gateway 💬
What: A 'translator' for different language models.
Why: Lets you switch between models without re-coding everything.
Vector DB 🗄️
What: Stores embeddings for super-fast data searches.
Why: Efficient searches are key for large datasets.
API Server ⚙️
What: The coordinator that handles user questions and generates answers.
Why: It connects all the pieces of the RAG system together.
Excited for Part 2: Coding with Cognita! 💻🚀